Return To Perceptual Hashing
Return to Perceptual Hashing!
As a follow up to my presentation about Perceptual Hashing of A/V content (slides available here), I thought I would put up a quick post and some tools as a resource for anyone who is interested in experimenting more with this technology!
As my original work with perceptual hashing was conducted at CUNY-TV, the database and integrated scripts were built around CUNY-TV systems and workflows. While the original tools are all available within the microservices repository used at CUNY, I though it might lower the barrier to experimentation if I peeled out the tools related to hashing into their own resource.
Right now, this is in a little bit of a quick and dirty form, with some simplifications and changes to the CUNY scripts (more on that later), but it should serve as a means to quickly create a hash database to do some testing with.
Tool for experimentation
I have created a repository at pugetsoundandvision that contains some basic scripts to create and configure a database to store perceptual hashes, generate and report hashes from source files and query the database for similar content. It can be found at:
https://github.com/pugetsoundandvision/perceptual
As I have been experimenting a bit with using hamming distance to compare hashes rather than the exact content match queries used in the CUNY tools, these experimental scripts differ from the CUNY tools in a couple ways.
- Currently instead of storing all five
bagofwordscomponents of the rough hash, only the first is being stored. This hash is broken up into 9 columns in the Database that represent 27 character subsets of the original binarybagofwords. - Hashes are now stored as decimal numbers instead of binary numbers. This allows for the same amount of data to be stored in less characters in the database.
- The query now searches for matches within a hamming distance of 2 using the following query method:
BIT_COUNT(hash1 ^ '${hashdec1}') + BIT_COUNT(hash2 ^ '${hashdec2}') ... <= 2"
- For the time being output has been massively simplified compared to the CUNY implementation. There is no visual preview output in these scripts. Output is limited to the terminal and contains mediaid, in frame, out frame and the first two hash columns for any matches discovered.
Installing and using tools
The tools depend on having both MySQL and FFmpeg already installed, so if you don’t have those that is your first step! (Also, currently these tools only work in Mac or Linux systems).
The tools can either be downloaded as a ZIP from github or with the command git clone https://github.com/pugetsoundandvision/perceptual.git
Create/Configure DB
Once downloaded, from within the perceptual directory run the command ./createfingerprintdb.sh. This will walk you through the process of creating a database, user and login profile for fingerprint storage/query. You will need to enter your MySQl root password a couple of times, and at the end it will output a command that you must run to create the login profile. You will run this command, followed by the password you selected for your user during database creation. Once this is done, the script should have automatically stored the database and login information in the FINGERPRINTDB_CONFIG.txt file. If anything needs to be changed you can manually edit this file in a text editor.
Create/Store Hashes
Once the database has been created you can start populating it with perceptual hashes! To do this (again from within the perceptual directory) run ./makefingerprint.sh INPUTFILE. This can be run on any kind of video file, and the input doesn’t have to be in the same directory. The script does need the full absolute file path, so it works best if after typing ./makefingerprint.sh you type a space and then drag your file into the terminal window. Don’t forget the space! This script will generate a full fingerprint (stored in a sub-directory in the same location as the input file) and report the bagofwords information to the database.
Query Hashes
Once you have some perceptual hashes stored in the database, you can query against it using the searchfingerprint.sh script. This script allows you set an in point and out point for fingerprint comparison so shorter subsections of videos (such as individual scenes) can be quickly compared. An example of this would be ./searchfingerprint.sh -i 30 -o 60 INPUTFILE. This command would create and compare fingerprints for content starting at 30 seconds and ending at 60 seconds in the input file. To run a comparison against a whole input file you would use ./searchfingerprint INPUTFILE.
If matching content is discovered, the output will look something like
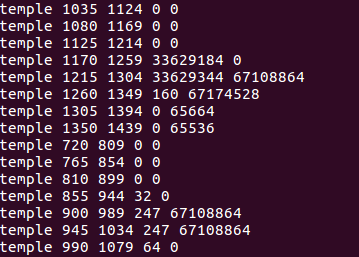
where the first column is the mediaid (yes I am still using Temple of the Dog as my test file), the second column is the in frame of the matching segment, the third is the out frame of the matching segment, and the fourth and fifth are the first two elements of the matching hash.
Good luck!
This repository was developed as a starting point for some research/experimentation with perceptual hashes. I am planning on modifying it to store more hash information and to be faster (probably ultimately rewriting the scripts in a different language such as Ruby). I hope this is helpful for anyone who wants to give hashing a try - let me know any questions, comments or successes you may have!